
Retrieval Augmented Generation (RAG): Chatten mit deinen eigenen Daten
Du möchtest neue Angebote und Services entwickeln? Mehr Engagement erzielen und die Bindung an deine Inhalte stärken? Egal ob Fachartikel, Bücher, Datenbanken oder Archive: Mit unseren RAG-basierten Lösungen verwandelst du deine Content- und Datenbestände in dialogfähige, dynamische Wissensquellen.
Unsere Frage-Antwort-Systeme sind sofort einsatzbereit, lassen sich durch Standard-APIs nahtlos integrieren und flexibel anreichern. Du steuerst Inhalte präzise nach Themen und Domänen – für Antworten, die exakt zu deinem Fachgebiet passen.
Mach dein Wissen natürlichsprachig zugänglich: Interaktive KI-Assistenten beantworten Nutzerfragen in Echtzeit – kontextsensitiv, verlässlich und auf Basis deiner internen und externen Inhalte.
Zugleich erhältst du wertvolle Einblicke direkt aus der Nutzung, die ein kontinuierliches Engagement ermöglichen: quantitative Performance-KPIs zu Nutzung und Conversions sowie qualitative Insights zu Nutzerfragen, -intentionen und Themen-Clustern.

Warum RAG und Frage-Antwort-Systeme? Weil Fakten zählen!
Generalistische Chatbots wie ChatGPT beeindrucken – aber verzerren oder erfinden auch gerne Inhalte. Für Fachverlage, die auf Präzision und Verlässlichkeit angewiesen sind, ist das eine echte Hürde. Unsere RAG-basierte Frage-Antwort-Lösung kombiniert die Möglichkeiten generativer KI mit der Sicherheit eigener Datenbestände: Bevor eine Antwort generiert wird, durchsucht das System gezielt deine Daten- und Content-Pools – und formuliert auf dieser Grundlage belastbare, kontextsensitive Antworten in natürlicher Sprache.
Der entscheidende Vorteil: Unsere Lösung kombiniert generative KI mit semantischer Suche, neuronalen Retrieval-Methoden sowie einem leistungsstarken Parsing. So werden selbst tiefere Bedeutungszusammenhänge in komplexen Datenquellen erkannt – ob Fachartikel oder Archivmaterial.

So funktioniert ein RAG-basiertes Frage-Antwort-System in der Praxis – am Beispiel eines Fachverlags
Ein Nutzer sucht nach aktuellen Informationen, um seine B2B-Marketingstrategie zu entwickeln, wobei der Fokus auf Paid Newsletter und den Einsatz von KI-Agenten liegen soll. Bislang hätte er sich durch eine Vielzahl an Heftarchiven, Dokumenten und Schlagwortlisten klicken müssen – mit Glück wären passende Artikel zu seiner spezifischen Frage dabei gewesen.
Mit einem RAG-basierten Frage-Antwort-System läuft das anders: Der Nutzer stellt dem System seine Frage – und erhält in Sekundenschnelle eine konkrete, verständliche und einwandfreie Antwort. Die generative KI durchsucht hierfür das interne Verlagsarchiv, bestehende Fachpublikationen und Sonderausgaben, filtert relevante Inhalte heraus und formuliert eine individuelle Antwort – verständlich, präzise und auf den Punkt. Dabei bleibt die inhaltliche Qualität stets gesichert: Es werden alle gewünschten Inhalte durchsucht und passgenau aufbereitet.
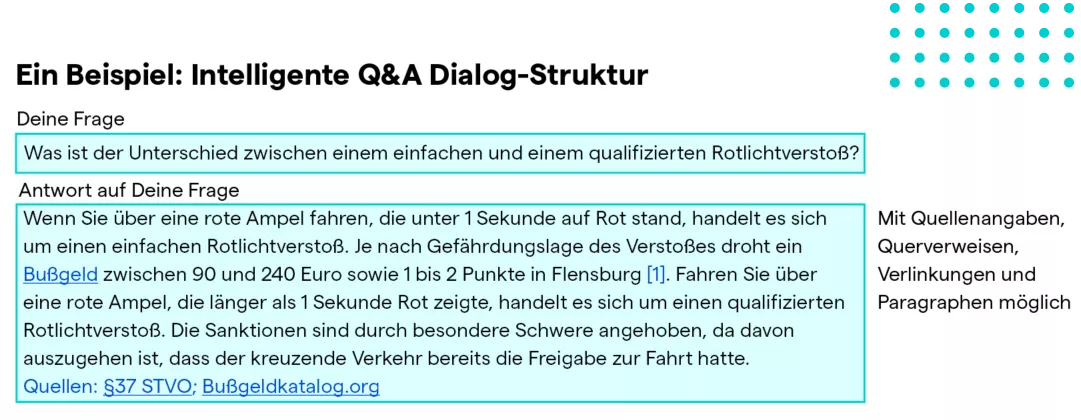
Und noch besser: Das Frage-Antwort-System liefert nicht nur präzise Antworten, sondern verlinkt direkt auf die passenden Artikel, verweist auf relevante Ausgaben und kann Sonderpublikationen gezielt zum Kauf oder als Abo-Upgrade anbieten. So entstehen völlig neue Nutzungserlebnisse – persönlich, interaktiv und konversionsstark. Das RAG-System wird zum digitalen Vertriebsassistenten für Content-Angebote!


Use Cases mit RAG-basierten Frage-Antwort-Systemen
Die Anwendungsfälle mit RAG und unseren wissensbasierten Systemen sind vielfältig:

Frage-Antwort-Systeme mit RAG: Fachwissen effizient nutzbar machen
Mit unseren RAG-basierten KI-Anwendungen machst du dein Expertenwissen bedarfsgerecht zugänglich:




Warum ein Frage-Antwort-System von Retresco?
|
Retresco RAG-basiertes System
|
ChatGPT & vergleichbare Systeme
|
||
|---|---|---|---|
| Architektur | Agentenbasierte KI: Mehrstufige Orchestrierung von Retrieval, Reasoning & Generierung für themenspezifische Informationshubs inkl. interne und externe Datenbanken und APIs als Quellen zur Beantwortung von Nutzerfragen | Herkömmliches LLM-Prompting oder einfaches RAG: Retrieval & Generierung meist linear ohne agentische Steuerlogik | |
| Abrufprozesse | Kontextsensitive Auswahl von Quellen, Dokumenttypen & Antwortformaten je nach Nutzerintention | Vordefinierte Such- oder Embedding-Strategien mit begrenzter Kontextdifferenzierung | |
| Datenintegration | Nahtlose Integration in CMS, Archive, Paywalls, Content-Hubs & Wissenssysteme per API | Integration abhängig von Plattform-Features oder individuellen Eigenentwicklungen | |
| Externe Datenquellen | Agentenbasierte API-Integration externer Daten (z. B. Datenbanken, Events, Normen, Statistiken) für maximale Antworttiefe | Externe Daten nur durch Plugins/Tools oder manuelle Integration, meist ohne orchestrierte Agentenlogik | |
| Nutzerinteraktion | Dialogsystem mit Feedback-Loops, Bewertungen & kontinuierlicher Optimierung aus Nutzerinteraktionen | Klassischer Chat-Dialog ohne integriertes Feedback- oder Optimierungsmodul | |
| Chat-Historie | Strukturierte, benennbare Chat-Verläufe mit Wiederauffindbarkeit & Wissensspeicherung | Sitzungsbasierte Historie ohne strukturierte Wissensorganisation für Fachkontexte | |
| Kontextverständnis | Tiefes Domänenverständnis durch semantische Suche, Quellenvalidierung & mehrstufige Antwortableitungen | Kontextabhängig von Prompt & Trainingsdaten, begrenzte Domänenspezialisierung | |
| Inhaltsqualität | Verlässliche Antworten aus kuratierten Fachinhalten mit Quellenreferenzen & Human-in-the-Loop-Abläufen | Quellenabhängig von Retrieval-Setup oder Modelltraining, Transparenz variabel | |
| Personalisierung | Domänen-, Titel-, Zielgruppen- & Produkt-spezifische Konfiguration für Fachverlagsangebote | Personalisierung meist nur über Prompting oder generische Systemparameter | |
| Automatisierung | Automatisierte Content-Gewichtung & Priorisierung nach redaktionellen und strategischen Vorgaben | Keine integrierte redaktionelle Steuerlogik | |
| Skalierbarkeit | Für große Fachcontent-Bestände, strukturierte Daten & Multiformat-Ausgabe optimiert | Skalierung abhängig von Plattform-Limits & Kontextfenstern | |
| Analyse & Insights | Detaillierte Nutzungs-, Themen- & Fragenanalysen inkl. Performance-Visualisierung oder API-Export | Nutzungsanalysen plattformabhängig, selten fachlich auswertbar | |
| Nutzer-Feedback | Integriertes Nutzerfeedback zur kontinuierlichen Qualitätsverbesserung & Optimierung | Feedback nicht systemisch in Wissensbasis integriert | |
| Design | Adaptives Chat-Widget: Vollständig an Verlag-UX/CD anpassbar & markenkonforme Einbindung mit Logos, Farben, Typografie, Labels & Disclaimer | Standard-UI oder individuelle Eigenentwicklung erforderlich | |
| LLM-Anbindung | LLM-agnostisch: Nutzung beliebiger Open-Source- oder proprietärer Modelle je nach Use-Case | An Plattform- oder Anbieter-Modelle gebunden | |
| Mehrsprachigkeit | Fachsprachlich optimierte Mehrsprachigkeit inkl. SEO-Lokalisierung & semantische Entitäten | Mehrsprachigkeit modellabhängig, SEO-Feinsteuerung begrenzt | |
| Weiterentwicklung | Branchenspezifische Feature-Roadmap für Fachverlage | Plattform-Roadmap ohne Verlagsspezialisierung | |
| Support | Persönliche Betreuung durch KI-, SEO- & Fachverlags-Expert:innen im DACH-Raum | Generischer Online-Support ohne fachspezifisches Know-how | |
