Blog
Artikelarchive als interaktive Informationsangebote: Neue Chancen für Medienhäuser durch RAG

Harald Oberhofer
Head of Marketing, Retresco
Artikelarchive galten lange als notwendiges Übel – kostspielig im Aufbau, aufwendig in der Pflege und oft schwer zugänglich. Doch mit dem Aufkommen von RAG („Retrieval-Augmented Generation“) erleben Artikelarchive eine fundamentale Neubewertung: Sie entwickeln sich vom passiven Datenspeicher zu einem aktiven, interaktiven Wissensraum – und werden damit zur strategischen Ressource für Medienhäuser.
Für Entscheider:innen und Praktiker:innen in Verlagen stellt sich inzwischen nicht mehr die Frage, ob sich Artikelarchive nutzen lassen, sondern vielmehr, wie sie sich intelligent erschließen und monetarisieren lassen.

Warum Artikelarchive strategisch wichtig für Medienhäuser sind
Artikelarchive sind weit mehr als historische Ablagen und zurückliegende Artikelbestände. Sie enthalten nicht nur wertvolle Inhalte, sondern auch Muster: Entwicklungen über Jahre, wiederkehrende Narrative, belastbare Quellen und einzigartige Perspektiven.
Gerade in Zeiten generativer KI entsteht hier ein entscheidender Wettbewerbsvorteil:
- Medienarchive sind nicht öffentlich zugänglich
- Sie können nicht einfach von offenen KI-Suchen genutzt werden
- Sie spiegeln meist längere regionale oder fachliche Expertise wider
Während KI-Suchen wie ChatGPT oder Google Gemini auf öffentlich verfügbare Daten angewiesen sind, verfügen Medienhäuser über exklusive Inhalte, die sich weder scrapen noch lizenzieren lassen. Genau hier setzt RAG an.
Retrieval-Augmented Generation und Information Retrieval: Die Grundlage moderner Artikelarchive
RAG verbindet leistungsstarkes Information Retrieval, semantische Verfahren und generative KI. Das Ergebnis: Inhalte werden nicht nur gefunden, sondern verstanden, kontextualisiert und interaktiv aufbereitet.
Statt zeitaufwendiger Keyword-Suchen entstehen völlig neue Nutzererfahrungen:
- Fragen in natürlicher Sprache
- Kontextsensitive Antworten aus dem gesamten Artikelarchiv
- Automatisierte Zusammenfassungen und Analysen
- Interaktive Dialoge mit journalistischen Inhalten
Beispiele für solche Fragen:
- „Wie hat sich die Sicherheitslage seit 2024 international verändert?“
- „Wie haben sich Mietpreise in unserer Region in den letzten 15 Jahren entwickelt?“
- „Welche Entwicklungen gab es bei der Umweltqualität in meiner Stadt?“
RAG erkennt Zusammenhänge über Jahre hinweg und verknüpft Inhalte, die herkömmliche Suchsysteme nicht zusammenbringen. Die semantische Erschließung tritt an die Stelle einer starren Keyword-Logik.
Artikelarchive als interaktive Wissensräume für bessere Nutzerbindung
Mit RAG werden Artikelarchive erstmals wirklich dialogisch zugänglich – und zwar nicht nur für Nutzer:innen, sondern auch für Redaktionen.
Externe Nutzung: Neue Angebote in Medienarchiven
Für die Nutzerschaft lassen sich völlig neue Interaktionsformen etablieren:
- Chatbots auf Basis journalistischer Inhalte
- Personalisierte Themen-Dossiers
- Dynamische Informationsanalysen und Zeitverläufe
- Explorative Rechercheumgebungen
Das Ergebnis: höhere Nutzungstiefe, mehr Engagement sowie ein klar differenzierbares Angebot.
Interne Nutzung: Produktivität und Insights steigern
- Auch innerhalb der Redaktionen bieten Artikelarchive erhebliche Potenziale:
- Analysen von Nutzungsverhalten und Themen-Performance
- Rekonstruktion und Nutzung von Beziehungen, Kontakten und Quellen aus Artikelarchiven
- Schnelle Recherchen durch Zugriff auf vergangene Berichterstattung
Das Resultat: Archive entwickeln sich vom statischen Pressearchiv zum operativen Werkzeug für die Redaktionen.
Geschäftsmodelle mit Medienarchiven: Vom Kostenfaktor zur Erlösquelle
Lange Zeit wurden Artikelarchive primär als Kostenblock betrachtet. Mit RAG ändert sich das grundlegend. Artikelarchive monetarisieren wird zur realistischen Option – und zwar in vielerlei Hinsicht:
- Premium-Zugänge
Exklusive, interaktive Archivfunktionen als Teil von Abomodellen. - Chatbot-Services
Spezialisierte Assistenten (z. B. Gastro, Finanzen, Immobilien, Gesundheit) auf Basis verlagsinterner Inhalte. - Lizenzierung
Bereitstellung strukturierter Inhalte und Analysen für Unternehmen oder Institutionen. - Neue journalistische Formate
Vom einzeln auffindbaren und lesbaren Artikel hin zu interaktiven, vernetzten Wissensangeboten.
Kurzum: Interaktive Artikelarchive bilden die Basis für neue digitale Geschäftsmodelle.
Praxisbeispiele: Neue Angebote in Medienarchiven dank RAG
The Economist: Vom Artikel zum Wissensraum
Durch den Einsatz RAG-basierter Artikelarchive wandelt sich „The Economist“ gerade vom klassischen Medienhaus zu einem interaktiven Wissensanbieter. Mithilfe von Tools wie NotebookLM werden historische Inhalte analysiert, kuratiert und in neuen Formaten zugänglich gemacht – etwa als thematische Dossiers wie „The World Ahead 2025“ oder als durchsuchbare Archive zu langfristigen Entwicklungen wie „Globalisation since 1997“. Nutzer:innen können Fragen stellen, Zusammenfassungen generieren oder Inhalte explorativ erschließen.
Das neue Artikelarchiv eröffnet eine neue, personalisierte Rechercheumgebung für komplexe Themenfelder wie Wirtschaft und Geopolitik. Die Nutzungstiefe steigt deutlich: Statt Inhalte nur zu überfliegen, können Nutzer:innen gezielt nachhaken, Zusammenhänge verstehen und sich Inhalte individuell aufbereiten lassen. Zugleich wird das umfangreiche Archiv des Economist interaktiv nutzbar, kontextualisiert und effizient wiederverwertet.
Der Fokus liegt auf einer stärkeren Nutzerbindung sowie auf der Entwicklung neuer journalistischer Darstellungsformen, bei denen Dialog und Discovery stärker in den Vordergrund rücken als der lineare Konsum einzelner Artikel.
RAG trifft Redaktion: The Economist verwandelt sein Archiv in ein dialogisches Wissenssystem (The World Ahead 2025)
Allerdings bringt dieser Ansatz auch neue Abhängigkeiten mit sich. Durch die Nutzung externer Plattformen wie Google wird ein Teil der Kontrolle über Benutzeroberfläche und Interaktionen ausgelagert. Der strategische Vorteil exklusiver Inhalte – insbesondere im Sinne von RAG auf Basis eigener Artikelarchive – wird dadurch zumindest teilweise relativiert.
The Wall Street Journal: Antworten statt Artikel
Auch das „The Wall Street Journal“ geht über herkömmliche Artikelangebote hinaus und setzt auf einen themenspezifischen Chatbot, der konkrete Nutzerfragen im Steuerbereich beantwortet. Nutzer:innen müssen deshalb nicht mehr aktiv nach Einzelinformationen suchen, sondern erhalten ausformulierte Zusammenfassungen zu den gewünschten Themen. Inhalte werden kontextuell aus unterschiedlichsten Artikeln zusammengeführt, und an die Stelle des reinen Lesens treten natürlichsprachige Interaktionen.
Der Steuer-Chatbot „Lars“ verzeichnet monatlich tausende Interaktionen mit WSJ-Abonnent:innen. Die zugrunde liegende RAG-Technologie greift auf archivierte Berichterstattung seit 2018 sowie auf offizielle Quellen zurück. Hintergrund ist eine Vielzahl hochspezifischer Steueranfragen, mit denen Journalist:innen bislang konfrontiert waren und die sich manuell nicht skalierbar bearbeiten ließen. Statt einzelne Artikel zu durchsuchen, erhalten Nutzer:innen maßgeschneiderte Antworten – inklusive Follow-up-Möglichkeiten und zugeschnitten auf ihre jeweilige Frage.
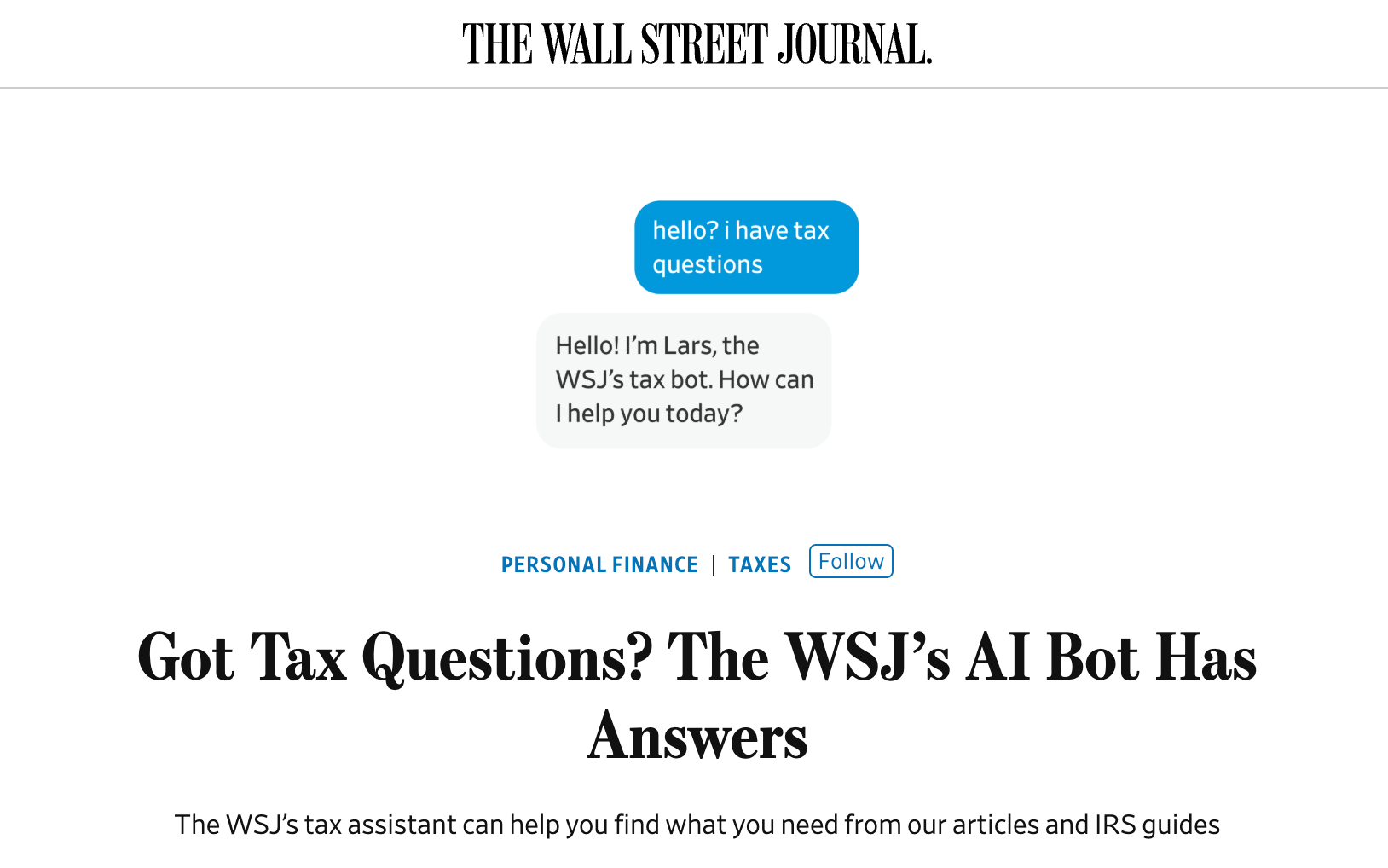
Der WSJ Steuer-Chatbot liefert maßgeschneiderte Antworten aus journalistischen Inhalten und offiziellen Quellen (Lars)
Trotz des hohen Nutzwerts bringt dieses Angebot auch Herausforderungen mit sich, da Themen wie Steuer- oder Finanzfragen hochsensibel sind. Das Wall Street Journal positioniert den Chatbot daher bewusst als unterstützendes Hilfstool und nicht als verbindliche Beratung.
Erfolgsfaktoren für die Umsetzung interaktiver Artikelarchive
Wer Artikelarchive erfolgreich transformieren möchte, sollte strukturiert und schrittweise vorgehen. Am Anfang steht eine gründliche Bestandsaufnahme. Dabei gilt es, den Digitalisierungsgrad der Inhalte zu prüfen, die Qualität der vorhandenen Metadaten zu bewerten. Denn ohne eine saubere und konsistente Datenbasis bleibt jedes noch so leistungsstarke RAG unter seinen Möglichkeiten.
Im nächsten Schritt empfiehlt es sich, semantische Verfahren gezielt zu testen. Dazu gehört die Evaluation von Vektordatenbanken ebenso wie die Entwicklung erster RAG-Prototypen. Es empfiehlt sich, mit kleineren, überschaubaren Datenmengen zu starten, um erste Insights zu gewinnen und Risiken zu minimieren. Zugleich sollte frühzeitig eine interne Nutzung etabliert werden, damit Erfahrungen direkt in die Weiterentwicklung einfließen können.
Parallel dazu spielen Analysen von Themen-Clustern eine wichtige Rolle. Inhalte können automatisiert kategorisiert werden, während das erfasste Frageverhalten wertvolle Hinweise zu Themeninteressen, Informationslücken und Nutzungsmuster gibt. Ergänzend dazu helfen aktives Feedback sowie die Auswertung von Korrelationen zu Abonnements und Kündigungen, ein tieferes Verständnis für die Relevanz einzelner Themenbereiche zu entwickeln.
Auf dieser Grundlage lassen sich schließlich konkrete Angebote entwickeln. Nach einer erfolgreichen internen Nutzung bieten sich etwa Chatbots zu Spezialthemen oder einzelnen Ressorts als niedrigschwelliger Einstieg an.
Fazit: Artikelarchive als Schlüssel zur KI-Strategie von Medienhäusern
Artikelarchive bilden das Fundament der KI-Strategie moderner Medienhäuser und sind ein zentraler Treiber ihrer digitalen Transformation. Durch den Einsatz von RAG und Information Retrieval werden solche Archive nicht nur leichter zugänglich, sondern auch intelligenter nutzbar und wirtschaftlich erschließbar. Inhalte, die bislang ungenutzt blieben, lassen sich so in neue Kontexte einbetten und bereitstellen.
Gut strukturierte Medienarchive ermöglichen es, umfangreiche Artikelbestände systematisch zu erschließen und strategisch zu nutzen. Medienhäuser schaffen damit die Grundlage für effizientere Redaktionen, innovative Nutzerangebote und neue Erlösmodelle. Der entscheidende Wettbewerbsvorteil liegt dabei nicht allein in der Technologie, sondern vor allem in den eigenen Inhalten. Dieser wertvolle Content ist bereits vorhanden – in den verlagsinternen Archiven – und kann gezielt aktiviert werden.
Hast du Fragen, Anmerkungen oder Feedback zur Nutzung und Umsetzung von Artikelarchiven? Sprich uns an – unsere KI-Expert:innen melden sich gerne bei dir!


